


A game of trust
Exploring basic machine psychology through the prisoner's dilemma

In an iterated prisoner’s dilemma game, would an LLM regurgitate what it learnt during its training and simply adopt a Tit for Tat strategy, or would it deviate under some circumstances? This is the question Kenneth Payne and I asked ourselves a few weeks ago. Coincidentally, shortly afterward, the question resurfaced during one of Ken’s talks on military AI at a conference in Copenhagen. So we decided to investigate.
. Purchase © 2013 C. Herscovici, Brussels / Artists Rights Society (ARS), New York")
You may have read Ken’s posts on the topic already. If you have not, give it a go: it sets the stage well for what I am discussing here. A quick introduction to the settings I am using first:
An Iterated Prisoner’s Dilemma lasting 100 rounds. Players are not aware of the round limit.
Players include 6 predetermined strategies (Always Cooperate, Always Defect, Random, Win-Stay Lose-Switch, Tit for Tat, Grim Trigger) and a number of LLMs.
Each LLM agent is reached through API calls and presented with a brief prompt recalling the history of the match they are playing as well as the reward matrix. They are then asked to answer with a single letter (C or D) to cooperate or defect.
Format is similar to Axelrod’s famous tournament, a round-robin (everyone plays against everyone once) with the following reward matrix below:

My first runs focused on answering the question I initially presented: would an LLM blindly follow Tit for Tat? Ken tested GPT4o, and I tested DeepSeek-R1 (since we are making thousands of API calls, our choice of model is strongly influenced by speed and cost per token, while balancing overall quality). We reached similar results:
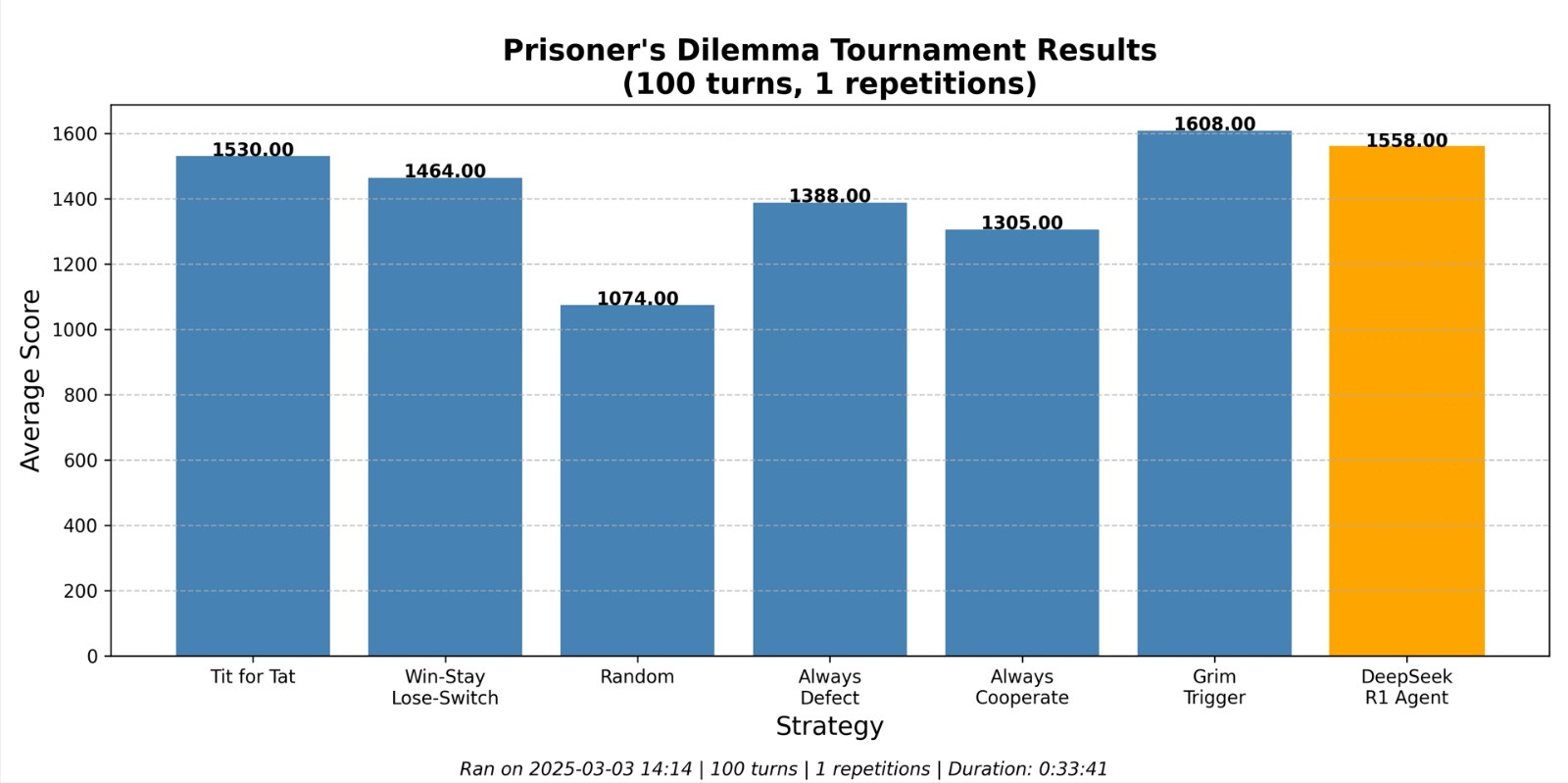
Although DeepSeek doesn’t reach the performance of Grim Trigger here (whose strategy is to cooperate until defected against, then defects permanently), it does better than Tit for Tat. Why is that? The key difference is about how those 3 players handle Random, who is the only non-deterministic player (apart from DeepSeek itself).
The optimal way to play against Random is to always defect. This is because there is no punishment for doing so, and 0 incentive to cooperate since it won’t alter Random’s behaviour anyway. Grim Trigger quickly adopts this behaviour. Tit for Tat does not since it is not inherently an exploitative strategy, it is just being reciprocal. But what about DeepSeek? Can it abuse Random? Turns out that yes, not as well as a pure extortion strategies, but well enough to outperform Tit for Tat on the finish line.
Thus, we have our answer to this first question: LLMs do not just follow a predetermined strategy, they are actually able to deviate to deal with non-linear opponents and, if needed, exploit them. We did not stop there though. The obvious follow-up question is: what happens when you bring more models into the tournament?

The LLM agents all perform fairly strongly, and are particularly civilised with each other, fully cooperating until the end. After all, why deviate from something that works? Those results are not too interesting as the difference in performance between them only stems from how well they exploited Random. So let’s add a little twist for the last run of this post and bring some noise into the mix:
From now on, for all players, there is a 5% chance that everytime a move is being played, it flips to the opposite action (i.e: after playing ‘Cooperate’, there’s a 5% chance that the move actually being played will be ‘Defect’). Players are NOT informed of this rule.
We want to see how each agent deal with this noise - will they spiral out of control into a fully defective playstyle after a single perceived betrayal, find their way back to cooperation, or behave more subtly?
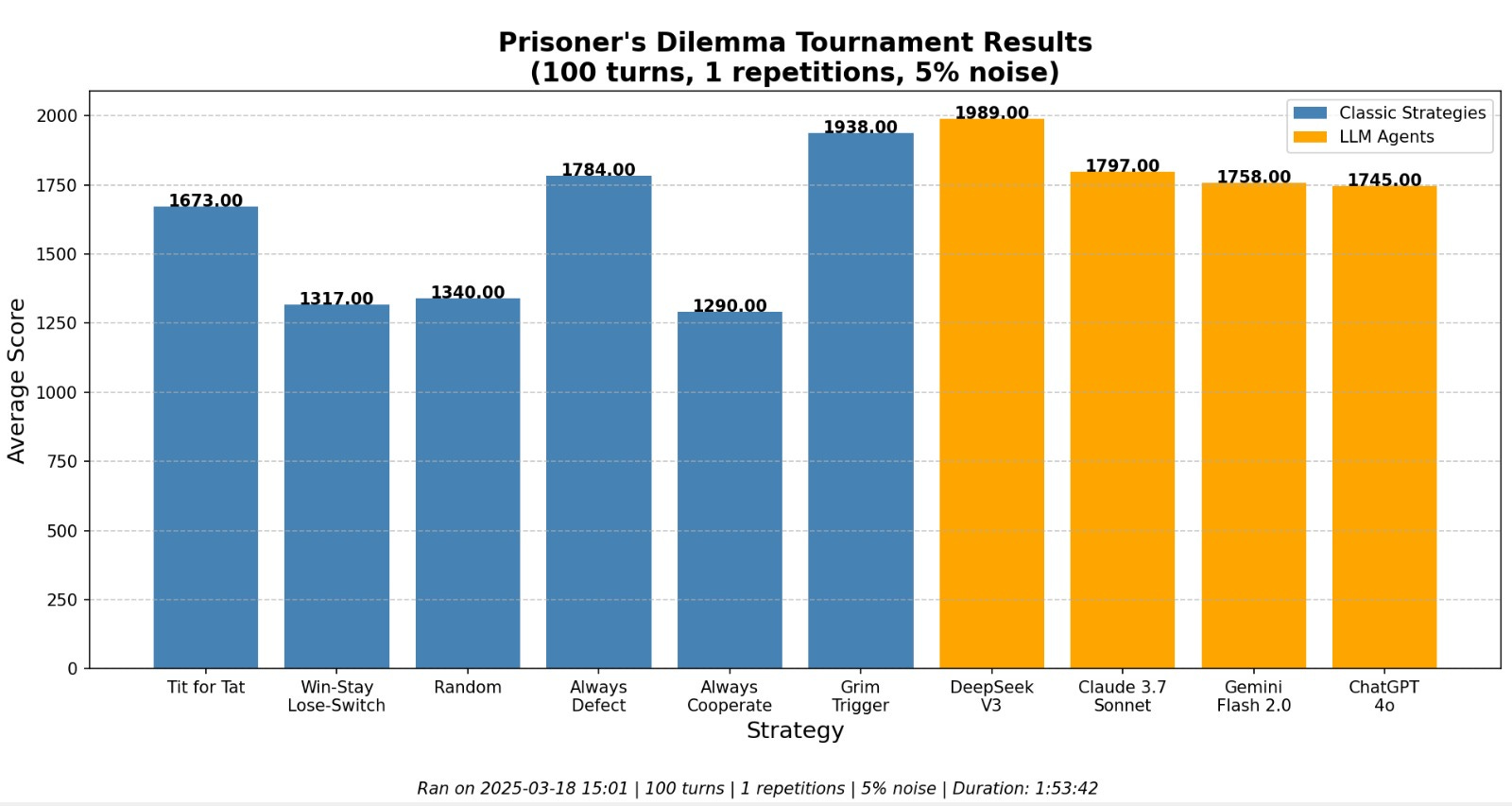
All of a sudden, we get something much more interesting. The LLMs stop cooperating so heavily and paranoia starts creeping in. Yet they behave differently from each other:
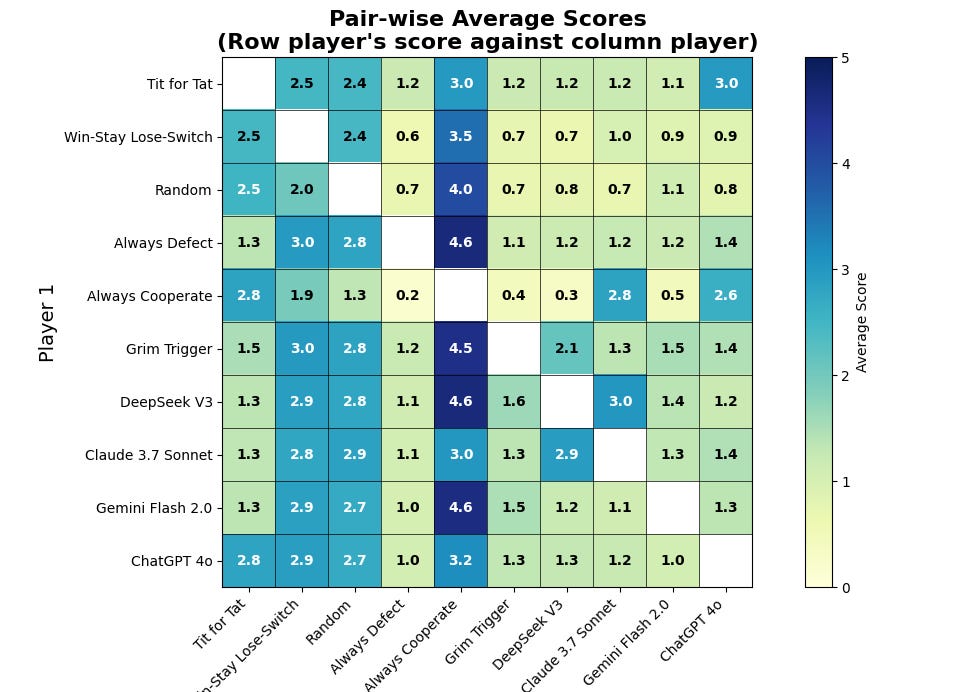
This tendency for paranoia is visible when checking their performance versus Tit for Tat. Tit for Tat is a mirror that reveals the true nature of its opponent. Gemini, Claude, and DeepSeek, all reach an average score of 1.3/5 against it (a fully defective match yields a 1/5 average score), which means they heavily defected. Yet, in contrast, GPT4o pursued a more civil path, scoring 2.8/5 (a fully cooperative match yields a 3/5 average score).
Gemini and DeepSeek both utterly exploited Always Cooperate as soon as they understood that it was not retaliating when they were defecting, reaching an almost perfect score of 4.6/5. Claude and GPT4o remained pacific.
In the inter-LLM heads-ups, all models converged toward defection, with the exception of Claude and DeepSeek who succesfully went back to cooperating together despite the occasional setbacks caused by the noise.
DeepSeek-V3 leaps ahead in the end thanks to being adaptive enough to cooperate with Claude despite the noise, while still exploiting weak play when it sees it (such as Always Cooperate). It even garners enough points to beat Grim Trigger overall.
So what can we conclude out of all this?
LLMs do not necessarily stick to strategies they have learned to be effective (not from experience like an RL model, but because it was explicitly stated to be effective in their training data) and can deviate from them when they spot encouraging circumstances.
When some noise is injected, making the matches less linear, they start adopting distinctive strategies while retaining a similar baseline. They seem to exhibit different behaviours and tendencies, with GPT4o being the most ‘pacific’ player and Gemini being the most ‘agressive’ player out of the 4 models I have involved here.
This last point is quite an important takeaway, since noises, frictions, uncertainty, are fundamentals of Strategy and cannot be avoided. Miscommunication happens, unintended effects are common, and if we ever are to involve LLMs in strategic decision-making, then understanding how they react to this and why really does matter, especially since all these models behave differently from one another.
The prisoner’s dilemma is indeed a very simple framework to investigate these questions, but a good starting point before diving into more complex games/environments.
Amusingly, while Ken and I were busy running these experiments, the idea of letting LLMs face each other in an array of games to judge their capabilities gained strong traction in the tech world as standard benchmarks start falling short of their goals. Building on this, I will present in my next post some of my work on LLMs playing Diplomacy and discuss what has been done in this area so far.