
Cicero in Context: Gameplaying AIs and the Future of AI-enhanced Wargaming [guest post]
Why gameplaying AIs are not all the same and what it implies - by Vincent Carchidi


Foreword by B. Alloui-Cros: The following piece by Vincent Carchidi assesses, in a very neat way, the main differences behind the architecture of some of the biggest breakthroughs in gameplaying AIs (AlphaGo, Libratus, Cicero…). Drawing from very up-to-date resources, his analysis offers deeply valuable insights into some of the paths wargaming-relevant AI research is taking today. Vincent kindly offered to publish his work here, and I am sure my readers will find it just as informative as I did.
Introduction
A recent report from the Alan Turing Institute1 centered on the technical, policy, and ethical challenges of artificial intelligence (AI) in contemporary wargaming highlighted numerous, ground-level challenges for the field: a valid methodology for human decision-making from which AI can model human behavior; over-trusting the outputs of AI-enabled agents; a lack of causal reasoning by AI agents; and insufficient contextual and situational awareness among AI agents, among others. The authors explicitly note that a conflation of automation and AI has “contributed to hype and confusion” beckoning a need for “greater technical literacy.”2 Such is the nature of this “nascent debate.”3
Confusion over technical concepts in AI and the hype surrounding this technology’s applications in defense is an enormously complex problem, making a clear-eyed assessment of AI’s applications in wargaming difficult. It echoes commentary from wargamers like Jon Compton who suggest that the use of machine learning algorithms in wargaming is an “infatuation” at the expense of “analytically robust” wargame designs.4
The purpose of this outlet is to cut through the confusion surrounding AI, wargaming, and strategy and put each in their appropriate contexts. To this end, Baptiste Alloui-Cros’ recent analysis5 of the Diplomacy-playing AI “Cicero” and its implications for wargaming clears the path. Cicero, released by Meta in November 2022, departed from a slew of AI achievements in gameplaying AI research by successfully combining strategic reasoning and natural language communication at human-level performance in Diplomacy.
Cicero’s unique design—which affords its distinctive, though limited, capabilities in Diplomacy—is directly relevant to the technical problems and confusions in wargaming and AI highlighted by the Alan Turing Institute’s report. This design should be grappled with in some level of technical detail by wargamers who are interested in the medium- and long-term applications of AI in wargaming for a simple reason: it is impossible to understand where relevant gameplaying AIs will go in the future without understanding where they are now.6
Building on Alloui-Cros’ analysis, this article puts Cicero in a broader gameplaying AI context, exploring the evolution of research in this field from the chess-playing Deep Blue to the go-playing AlphaGo and poker-playing Libratus. With this background established, we will clearly assess what direction the most wargaming-relevant AI research is taking—and realistically can take.
AIs That Strategize, But Don’t Speak
Cicero was developed for the purpose of playing the board game Diplomacy. Diplomacy, like chess, go, and poker has long been considered7 a benchmark8 for machine intelligence. But differences in the structures of each game reveal critical differences in the capabilities required to succeed at them. To appreciate the distinctiveness of Cicero’s design—and what it means for wargamers—we must first understand its precursors. This will serve to contextualize what may be “the deepest and most extensive integration of language and action in a dynamic world of any AI system built to date”9 through Cicero for the benefit of a broad wargaming audience.
Chess
Chess represented an intriguing benchmark for machine intelligence. AI expert Murray Campbell, who was recruited by IBM in the late 1980s to develop a chess-playing AI, makes it easy to see why: “It’s known as a game that requires strategy, foresight, logic—all sorts of qualities that make up human intelligence.”10
Chess is a strategy game with specific rules governing the movements of each player as they try to checkmate their opponent’s King. Players move their pieces on the board one at a time, with information about the state of the board available to both. Different kinds of pieces are assigned different values, with the King’s value being infinite.11 These valuations provide the game with a particular level of structure in an otherwise enormous number of possibilities. While the number of possible moves in an entire game is staggering (roughly 10123), this structure allows players to cut down on the number of possibilities explored.
Armed with specialized abilities to search up to 100 million possible moves per second, IBM’s Deep Blue was unable to unseat human Chess grandmaster Garry Kasparov in 1996. This compelled researchers to up the ante—an upgraded version of Deep Blue possessed a specialized chip with an enhanced ability to evaluate possible positions for pawns, search up to 200 million options per second, and possessed greater internal information regarding positions, lines of attack, and other Chess concepts.12 In 1997, Deep Blue defeated Kasparov.
Go
Go is also a strategy game, but there are important differences that make it a different challenge for AI. While each player takes their turns asynchronously, the rules of the game are simpler. The aim for each player is to acquire as much territory (as many spaces) on the board as possible. Stones that are placed on the board remain unmoved until they are surrounded by an opponent’s stones. The sheer number of possible actions in a game of 150 moves is roughly 10360, dramatically more than chess’s 10123.13 The ability to identify patterns becomes critically important.
But simply transferring the search techniques of Deep Blue to a go-specific context does not do the trick. Go is more complex, and it is also not clear how expert players decide their moves. Whereas in chess, pieces are given valuations that provide a level of structure to the game, go players will make moves in reference to informal impressions of “light” and “heavy” stones and board positions having a “good shape.”14 Such concepts cannot be readily translated into an algorithmic form the way Deep Blue was programmed with specific Chess concepts.
Many thus considered mastery over this domain to be the exclusive purview of human intuition and strategizing capabilities. That is, until AlphaGo defeated world champion Lee Sedol 4-1 in 2016.15
AlphaGo’s16 underlying architecture is not Deep Blue’s, but bigger; it’s different. A post-Deep Blue-era search algorithm known as the Monte Carlo tree search is critical.17 Simply imagine a tree-like structure that branches outward to simulate the pathways the player can explore—that, at its most basic, is Monte Carlo.18 This search algorithm was then combined by researchers with two neural networks—these networks were designed to select the next move from these pathways and to make predictions about the winner of the game based on the current configuration of the stones. The data these neural nets were trained on were a combination of expert moves by human players and self-play (playing against copies of itself).
{kind=link}
The later, more powerful AlphaGo Zero19 was trained purely through self-play while its single neural network was rewarded for wins and punished for losses. Despite the lack of human examples in its training data, AlphaGo Zero reached “superhuman performance.”20
Contrary to popular reporting, AlphaGo Zero does possess go-specific information, including perfect knowledge of the game rules as the Monte Carlo search algorithm simulated moves, the use of logical rules for scoring, and the structure of the go board’s 19x19 grid, among other information.21 The system’s pure self-play refers only to the training it underwent after researchers built in significant go-specific components.
Incredible as Deep Blue and the AlphaGo family are, none of these systems had to converse with human opponents like Kasparov and Lee—they simply had to excel on a strategic level. What about games in which the mental states of one’s opponents do matter for achieving victory?
Poker
Poker is a bit different than chess and go. While it does not require that players negotiate outcomes, it does demand “bluffing” —deceiving one’s opponents about the value of the hand one holds in the hope that they lay down their own, better cards—in a highly selective manner. It is not necessary that a player be in mental alignment with one’s opponents, but that they perform moves that compel their human opponents to adopt a mental state based on false beliefs. Poker is a game of imperfect information because players keep some information secret, thereby forcing all players to make moves without it.
The challenge was first met by the poker-playing agent Libratus developed at Carnegie Mellon University. Libratus defeated four of the world’s leading professional poker players in a 20-day tournament in 2017.22 It played only the two-player version of the game known as Heads-Up, No Limit Texas Hold‘em.
How23 it accomplished this represents a departure from Deep Blue and AlphaGo while building from a select few techniques. Libratus constructed an abstraction of the game it is playing called a “blueprint” which groups together bets and card combinations according to their similarities. Then, Libratus creates a “subgame” based on the blueprint which it then runs and solves in real-time, literally simulating an alternate game while the actual one continues. It assumes the opponent’s strategy will change and searches for strategies that will leave the opponent no better off than before (this minimizes the number of options it must search through). Libratus then searches for moves made by opponents that were not in the original blueprint and searches for new solutions while humans are breaking from the game. Libratus employs a modified version of the Monte Carlo search algorithm suited for Poker.24 The system must “balance actions appropriately, so that the opponent never finds out too much about the private information the AI has…bluffing all the time would be a bad strategy.”25
By 2019, Pluribus26 could beat human expert players in six-player, No-Limit Texas Hold’em with a fraction of the computational cost due to algorithmic improvements.
Cicero: An Agent that Strategizes and Speaks
Deep Blue, AlphaGo, and Libratus each engage in strategic reasoning, employing remarkable tactical proficiency from one move to the next in the service of an ultimate goal. But none must do what humans take for granted in the real world of strategy: combine their strategic reasoning capabilities with natural language communication. In Diplomacy, that is exactly what’s needed.
The objective of Diplomacy, set in pre-Great War Europe, is for each of the seven players to acquire a majority of supply centers on the map. Like Poker, this game is also one of imperfect information because players’ movements on the board occur simultaneously—every player receives the same information about others’ movements on the board at the same time. Each military unit moved on the board, furthermore, is of equal strength. These aspects represent the strategic dimensions of the game.
Diplomacy’s distinctive feature is what happens prior to these actions. Players are forced to negotiate with one another through free-form dialogue. In web-based Diplomacy, this dialogue is text-based and each player chats privately. These negotiation phases are necessary for any player to acquire most supply centers, as it is where they communicate their intentions, plans, goals, and concerns to one another. Crucially, players can artfully deceive one another and must be on the lookout for potential betrayals. These aspects represent the natural language dimensions of the game.
The challenge Diplomacy presents for AI is grand. An agent must construct plans that align with the goal of acquiring supply centers. In doing so, it must communicate its plans (its intents) with discerning humans. The agent must therefore speak in a human language, such as English, in a way that is grounded in the context of the Diplomacy world. But it is not enough that the agent simply speaks English within the Diplomacy context—it must use its language to consistently communicate its intents to humans who are on the lookout for deceit, betrayals, and cooperative opportunities. More than this, the agent must fend for itself in a competitive world by ensuring that it does not simply give in to a human’s threat or manipulation. Its communications must, finally, remain aligned with the actual moves made by both the agent and human players as the configuration of the board changes over time.
Meta AI’s Cicero27 achieved this at human-level—but not superhuman-level—performance in Blitz Diplomacy, a version where the time for negotiations is limited to five minutes. It ranked within the top 10% of multi-level human players.28 The most important caveat here is that Cicero has not yet “mastered” Diplomacy. But, with limitations in perspective, this system’s achievements are remarkable. How does Cicero do it?
On a high-level view, Cicero’s architecture can be visualized according to the needs of the agent in Diplomacy—as a division between a planning engine that handles strategic reasoning and a dialogue agent that handles natural language communication. Between them is a highly specific mechanism designed to unify these components, while the planning engine asserts control over the dialogue agent. The unifying mechanism reviews dialogue history and board states to predict likely actions by other players. This process is then used to generate Cicero’s agent’s intents which allows it to construct its own goals. With planning established, the information is fed into the dialogue agent so that message generation between Cicero and other players is kept aligned with the strategic aims of the agent.29
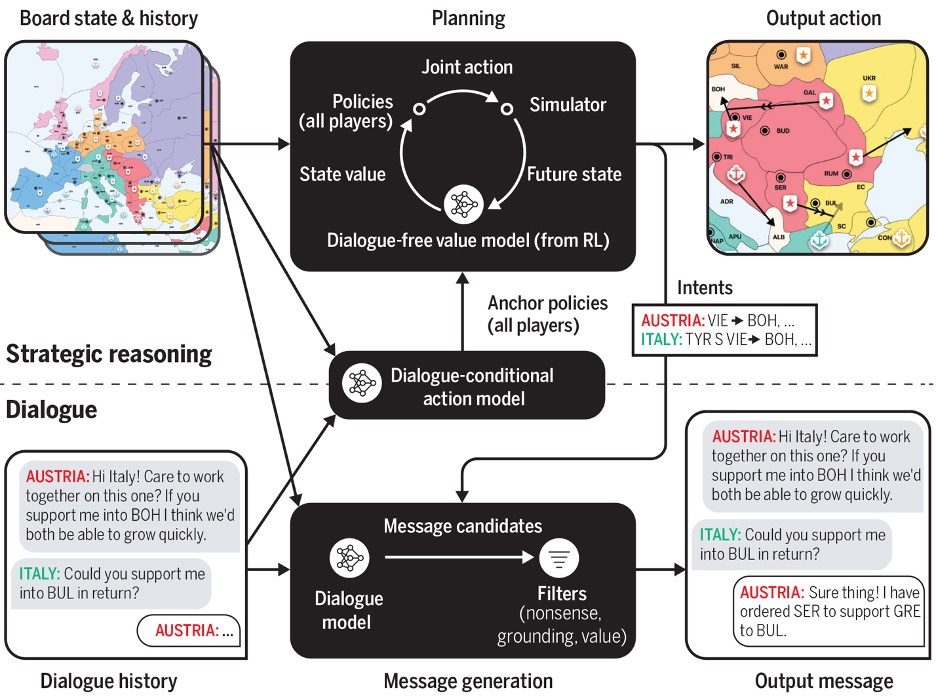{kind=link}
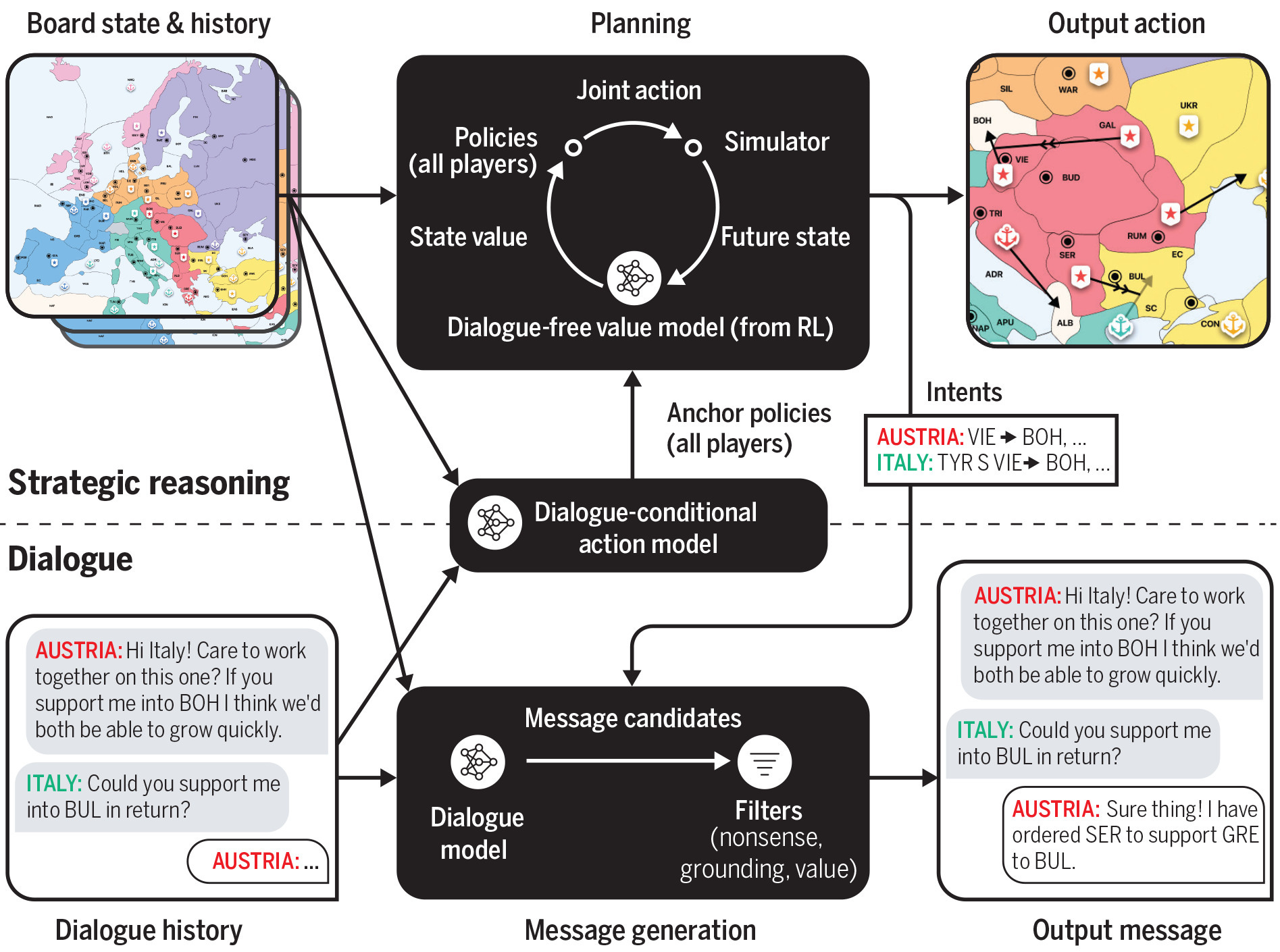
A low-level overview can have multiple different forms. While Cicero does make use of training techniques like self-play and reinforcement learning (used by AlphaGo and Libratus), its architecture is extremely complex. Alloui-Cros’ analysis of Cicero drew attention to the ‘metagame’ knowledge possessed by Cicero, which he deems “incredibly advantageous” due to Diplomacy’s rigid structure (there are patterns that can be detected over many games, revealing strategies that benefit those who are aware of them).30 This knowledge takes the form of 125,261 games of Diplomacy acquired through webdiplomacy.net. 40,408 of these games contain dialogue totaling 12,901,662 messages exchanged between human players.
How does Cicero use this data? A prominent use was for the dialogue agent that is responsible for natural language communication (i.e., negotiations). This agent is underpinned by a pre-trained generative large language model (LLM). Meta AI researchers report that since fine-tuning LLMs works well for the generation of human-like dialogue, the mindset going into the dialogue agent’s build was, “let’s do as much with this as possible.” They thus fine-tuned the LLM on the dialogue data collected via webdiplomacy.net. The researchers also labeled a select number of human messages to represent intents, which themselves reflect planned actions for Cicero and its “speaking partner” (and automatically augmented the dataset with these intents). This produces an LLM that speaks the language of the Diplomacy world—a dialogue agent.31
LLMs, however, are known to be easily manipulated by humans (an especially weak feature in a game with competitive elements), frequently inconsistent with their own outputs, lacking the precision of human language use (which is poorly suited for complex negotiations), and detached from an internal model of the world they are interacting with (whether that world is the real one humans inhabit or the Diplomacy board). The dialogue agent speaks the Diplomacy language, then, but is unprepared for human-level play.
This is where the complexity comes into view. Both pre-Cicero Diplomacy AI research and poker AI research was used to fit the dialogue agent and planning engine together, drawing principally from the idea that the Cicero agent cannot simply mimic other players’ behaviors nor can it engage solely in self-play training32 (leading to brittleness and ineffectiveness, respectively). Variations of an algorithm called “piKL”33 (pronounced “pickle”) were therefore developed: this algorithm, in its most basic form, models human behaviors while also selecting the optimal response given a set of possible actions across the environment for all players. It echoes the idea in poker that a player’s moves should minimize the possibility of regret later in the game while also recognizing that Diplomacy has a linguistic component.34
Enabled by variations of piKL, then, the planning engine controls the dialogue agent. It selects from the relevant intents in the construction of Cicero’s strategies, then has the dialogue agent generate a message candidate, sends the message to be filtered for quality purposes, and finally sends it to the receiving player. An action is then played.
Inhuman Design Leads to Human-Like Behavior
This is an enormously complex history. How should a professional wargamer make sense of it?
One way to frame the leap from strategic reasoning AIs—Deep Blue, AlphaGo, and Libratus—to combinatorial systems like Cicero is a transition from AIs with “inhuman” designs generating “inhuman” behaviors, in Paul Scharre’s35 useful characterization, to AIs with inhuman designs generating distinctively human behaviors. That is, human ends through inhuman means.
Deep Blue, AlphaGo, and Libratus did not have to negotiate with their opponents. No human being possesses the search capabilities of these systems or their internal chess, go, or poker representations. Yet, these systems can win at all these games against any human (in most cases36) even though their inhuman designs lead to inhuman performances. Cicero is different—it must behave like humans. Its design is inhuman, but it plays in ways that, as Alloui-Cros puts it, “impersonate a certain playing style”37 while relatively successfully aligning its natural language communication.38
To be sure, Cicero’s behavior is not fully human. Aside from Cicero being “narrow” AI (and sometimes contradicting itself), the agent is unusually honest. While world-champion Diplomacy player Andrew Goff calls this default into honesty “high-level play,” computer scientist Jordan Boyd-Graber believes this failure to “stab” opponents is holding the system back from truly mastering Diplomacy. The idea here is that deception in Diplomacy is rare but critical to truly mastering the game.39
I personally suspect this challenge can be met without radically upending AI—meaning Cicero may not have to truly learn how to read human intentions to master the game. Because the most basic framework for an alignment of natural language communication and strategic reasoning is in place for Diplomacy, it may be more feasible to tweak the comparatively richer planning engine to this end. Whatever the solution, though, Alloui-Cros is correct that agents like Cicero and AlphaGo Zero are advanced enough to give high-level players “new ways to think about” these games’ strategic principles.40
Conclusion: Cicero and the Future of Wargaming
This transition to technically inhuman AIs exhibiting human-like behavior is not merely relevant to AI research—it is directly relevant to understanding which applications of AI to wargaming will prove realistic. Categories of AI use-cases for wargaming identified by Knack and Powell41—including game design, game execution, game analysis, and game logistics—have varying but substantial dependence on this technical distinction.
Alloui-Cros argues that Cicero itself “is just ‘good enough’ in the social aspect of the game,” highlighting its “tactical prowess” over its linguistic abilities. This, nonetheless, “opens up promising paths for the use of AI in bespoke multiplayer wargames. In particular, its use of implicit signaling is extremely impressive and might constitute the main takeaway from Cicero’s experiment from a strategic point of view.”42
In the immediate term, Cicero suffers from the same, debilitating limitation that all other gameplaying AIs reviewed suffer from: it is confined to a single game, in this case Diplomacy. This means that in the short-term, we will not see Cicero transformed into a general-purpose wargaming agent.
This brings us to a critical point: the goal for wargamers is to avoid a common pathology surrounding AI and not futilely try to turn Cicero into a “universal solvent”43 the way large language models are being treated by popular (and sometimes expert) commentary. It is often said, but frequently ignored, that AI is more than just language models, or whatever happens to be in the headlines. Nowhere is this more evident than in Cicero’s unique architecture, the result of intentional design choices that step far outside much of the current zeitgeist in AI discourse.
Bringing the technical history of gameplaying AIs into a wargaming context is consistent with the “rediscovery” of educational wargaming, with which Sebastian Bae associates AI-enabled wargaming.44 And while it is still early days for research in Cicero’s lineage, the agent is referenced in the pursuit of “socially intelligent machines,”45 with some wishing for AI’s movement from optimization and predictive capabilities to direct learning from human intents. Such pursuits are a lively area of development in AI, as failed human interactions with a range of systems highly dependent on deep neural networks—such as self-driving cars46 or LLM-powered chatbots—spur a need for systems that can better reason in a manner interpretable by humans. Cicero is described in this vein by some researchers as a system with a “hybrid” architecture,47 an idea echoed by Gary Marcus and Ernest Davis48 who suggest Cicero’s design incorporates ideas from areas outside of machine learning. The system’s unique design potentially augurs the next wave49 in AI research.50
A few points, capturing these points, are useful to end this analysis:
(1) Gameplaying AIs Are Not One Thing: Each of our four AI agents explored here share certain fundamental features but are the results of intentional design choices by human researchers tackling different problems that require different solutions. What works for chess does not work for poker, and so on. Wargamers interested in the medium- and long-term adoption of AI for bespoke wargaming agents must be wary of commercial endeavors that cast the development of AIs as a singular technique becoming more computationally powerful over time—they are far more complicated than that, and professional wargaming will require this attention to technical detail.
(2) AI Is More Than Machine Learning: Machine Learning, and its most famous iteration deep learning, underpin most headline-grabbing successes in AI across domains including natural language processing and strategic reasoning research of the past decade—but, as we have seen here, a combination of techniques is responsible for Cicero’s even limited success. Wargamers should understand that more ambitious proposals for AI in wargaming—such as the inclusion of robust causal reasoning that interfaces with context-specific factors within the game—will likely require further research of this kind. (I write explicitly on this subject of combinatorial “innateness” here.)
(3) Inhuman AIs’ Human-Like Behavior is an Educational Boon: Paul Scharre hit the nail on the head in his description of AI: “Time and again, when AI systems achieve superhuman performance in games or simulations, their performance is not just better than humans. It is also different.”51 AI is inhuman and likely always will be. But AI will be increasingly forced to interact with humans in robust, explainable, and trustworthy ways and, harkening back to the above point, this will lead researchers to find new, inhuman architectures that support human-like behaviors and interactions. This should be fully embraced by wargamers as an educative aspect of AI, one advanced by Cicero.
(4) Future AI May Re-Define Wargaming: In the little-known world of linguistics, a contentious debate over the nature of human language is unfolding in part due to the public rise of LLMs. Stephen Wolfram sums up its core anxiety with the statement: “[W]riting an essay turns out to be a “computationally shallower” problem than we thought.”52 Cicero-like AIs in the medium- and long-term future may have a similar effect on wargaming. This may seem outlandish given the amount of time and effort devoted to the discipline’s analytic underpinnings, but I simply remind the reader that language has been studied one way or another for millennia and a relatively simple but massive language model has re-opened old intellectual wounds. Inhuman AIs performing in human-like ways—but always with their own, strange, alien twists—may lead wargamers down the same road.
Vincent J. Carchidi is a Non-Resident Scholar at the Middle East Institute’s Strategic Technologies and Cyber Security Program. His work focuses on the intersection of emerging technologies, defense, and international affairs. His opinions are his own.
Knack, Anna and Power, Rosamund. Artificial Intelligence in Wargaming. Alan Turing Institute: Centre for Emerging Technology and Security (June 2023): pp. 1-60. URL: https://cetas.turing.ac.uk/publications/artificial-intelligence-wargaming.
Ibid., p. 27.
Ibid., p. 5.
Compton, Jon. “A Tale of Two Wargames.” War on the Rocks (September 22, 2022). URL: https://warontherocks.com/2022/09/a-tale-of-two-wargames-an-entirely-fictitious-tale-of-wargaming-woe-and-tragedy.
Alloui-Cros, Baptiste. “Mastering Both the Pen and the Sword? Cicero in the Game of Diplomacy.” Baptiste’s Substack (May 26, 2023). URL: https://baptisteallouicros.substack.com/p/mastering-both-the-pen-and-the-sword.
Concomitant with this, the rise of Large Language Models in public discourse, while fascinating, effectively sucked the air out of the AI room in terms of public education and private funding.
Hewitt, Carl. “Planner Implementation Proposal to ARPA, 1972-1973.” MIT A.I. Laboratory (December 1971). URL: http://www.bitsavers.org/pdf/mit/ai/aim/AIM-250.pdf.
Kraus, Sarit and Lehmann, Daniel. “Designing and Building a Negotiating Automated Agent.” Computational Intelligence 11 (February 1995): pp. 132-171. DOI: https://doi.org/10.1111/j.1467-8640.1995.tb00026.x.
Marcus, Davis and Davis, Ernie. “What Does Meta AI’s Diplomacy-Winning Cicero Mean for AI?” Communications of the ACM (November 28, 2022). URL: https://cacm.acm.org/blogs/blog-cacm/267072-what-does-meta-ais-diplomacy-winning-cicero-mean-for-ai/fulltext.
Greenemeier, Larry. “20 Years After Deep Blue.” Scientific American (June 2, 2017). URL: https://www.scientificamerican.com/article/20-years-after-deep-blue-how-ai-has-advanced-since-conquering-chess/.
Nielsen, Michael. “Is AlphaGo Really Such a Big Deal?” Quanta Magazine (March 29, 2016). URL: https://www.quantamagazine.org/is-alphago-really-such-a-big-deal-20160329/.
Goodrich, Joanna. “How IBM’s Deep Blue Beat World Champion Chess Player Garry Kasparov.” Spectrum IEEE (January 25, 2021). URL: https://spectrum.ieee.org/how-ibms-deep-blue-beat-world-champion-chess-player-garry-kasparov.
Greenemeir. “Deep Blue.”
Michael. “AlphaGo.”
Borowiec, Steven. “AlphaGo Seals 4-1 Victory Over Go Grandmaster Lee Sedol.” The Guardian (March 15, 2016). URL: https://www.theguardian.com/technology/2016/mar/15/googles-alphago-seals-4-1-victory-over-grandmaster-lee-sedol.
DeepMind, “AlphaGo.” Google DeepMind. URL: https://www.deepmind.com/research/highlighted-research/alphago.
Silver, David et. al. “Mastering the Game of Go with Deep Neural Networks and Tree Search.” Nature 529 (January 27, 2016): pp. 484-489. DOI: https://doi.org/10.1038/nature16961.
A more complex overview would break this tree-like search process into four distinct steps: (1) The algorithm begins at the root node of the tree, then moves down as it selects the optimal nodes below until an endpoint is reached that does not represent the end of the game (these are the branch-like figures expanding outward); (2) Then create at least one additional node according to the available actions, and select the first among them; (3) Simulate a rollout from this new node until one that terminates the game is found; (4) Send this result back up the tree, updating the values of all relevant nodes. See, e.g., Ziad Salloum, “Monte Carlo Tree Search in Reinforcement Learning.” Towards Data Science (February 17, 2019). URL: https://towardsdatascience.com/monte-carlo-tree-search-in-reinforcement-learning-b97d3e743d0f.
DeepMind. “AlphaGo Zero: Starting from Scratch.” Google DeepMind (October 18, 2017). URL: https://www.deepmind.com/blog/alphago-zero-starting-from-scratch.
Silver, David, et. al. “Mastering the Game of Go Without Human Knowledge.” Nature 550 (2017): pp. 354-359. DOI: https://doi.org/10.1038/nature24270.
Carchidi, Vincent. “What Is Innateness and Does It Matter for Artificial Intelligence? (Part 2)” Towards AI (July 12, 2023). URL: https://pub.towardsai.net/what-is-innateness-and-does-it-matter-for-artificial-intelligence-part-2-477eda27e25d; Marcus, Gary. “Innateness, AlphaZero, and Artificial Intelligence.” ArXiv (January 17, 2018). URL: https://arxiv.org/abs/1801.05667.
Sprice, Byron, “Carnegie Mellon Artificial Intelligence Beats Top Poker Pros.” Carnegie Mellon University (January 31, 2017). URL: https://www.cmu.edu/news/stories/archives/2017/january/AI-beats-poker-pros.html.
Zhu, Jiren. “Libratus.” The Gradient (June 29, 2018). URL: https://thegradient.pub/libratus-poker/.
This version is called the Monte Carlo Counterfactual Regret Minimization (MCCFR) algorithm—an absolute mouthful indicating two things: that the “tree” representing the game is updated with regrets reflecting actions the agent should have taken and samples actions that a player regrets not taking. The algorithm chooses an action that is in proportion to the level of regret (i.e., the action not taken which would have led to a greater reward).
Brown, Noam and Sandholm, Tuomas. “Superhuman AI for Heads-Up No-Limit Poker.” Science 359 (2017): p. 418. DOI: https://doi.org/10.1126/science.aao1733.
Meta AI. “Facebook, Carnegie Mellon Build First AI that Beats Pros in 6-Player Poker.” Meta AI (July 11, 2019). URL: https://ai.meta.com/blog/pluribus-first-ai-to-beat-pros-in-6-player-poker/.
Meta AI. “Cicero.” Meta AI (November 22, 2022). URL: https://ai.meta.com/research/cicero/.
Meta Fundamental AI Research Diplomacy Team (FAIR), et. al. “Human-level Play in the Game of Diplomacy by Combining Language Models with Strategic Reasoning.” Science 378 (November 22, 2022): pp. 1067-1074. DOI: https://doi.org/10.1126/science.ade9097.
Ibid., p. 1068.
Alloui-Cros. “Mastering both the pen and the sword?”
Meta Fundamental AI Research Diplomacy Team (FAIR), et. al. “Human-level Play,” p. 1068.
See, Bakhtin, Anton, Wu, David, Lerer, Adam, and Brown, Noam. “No-Press Diplomacy from Scratch.” ArXiv (October 6, 2021). URL: https://arxiv.org/abs/2110.02924.
On the use of piKL in no-press Diplomacy, see Bakhtin, Anton, et. al. “Mastering the Game of No-Press Diplomacy via Human-Regularized Reinforcement Learning and Planning.” ArXiv (October 11, 2022). URL: https://arxiv.org/abs/2210.05492.
See, Meta Fundamental AI Research Diplomacy Team (FAIR), et. al. “Human-level Play,” pp. 1071-1073.
Scharre, Paul. “AI’s Inhuman Advantage.” War on the Rocks (April 10, 2023). URL: https://warontherocks.com/2023/04/ais-inhuman-advantage/.
Waters, Richard. “Man Beats Machine at Go in Human Victory over AI.” Ars Technica (February 19, 2023). URL: https://arstechnica.com/information-technology/2023/02/man-beats-machine-at-go-in-human-victory-over-ai/.
Alloui-Cros, “Mastering both the Pen and the Sword?”
One need not look far for examples of Cicero’s human-like behavior. Expert-level Diplomacy player Markus Zijlstra narrates his experience playing against multiple Cicero agents simultaneously, noting that when a Cicero agent cannot commit to a course of action, it generates plausible, grounded excuses for why it cannot do so. Another example comes from anonymous Cicero play. After an infrastructure failure at Meta—during which Cicero could not respond to other players—Cicero, as France, responds to England’s flurry of messages with: “i am on the phone with my gf.”
See, e.g., Perskov, Denis, et. al. “It Takes Two to Lie.” Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (July 2020): pp. 3811-3854. URL: https://aclanthology.org/2020.acl-main.353.pdf.
Alloui-Cros, Baptiste. “Does Artificial Intelligence Change the Nature of War.” Military Strategy Magazine 8 (Winter 2022): pp. 4-8. URL: https://www.militarystrategymagazine.com/article/does-artificial-intelligence-change-the-nature-of-war/.
Knack and Powell. AI in Wargaming, p. 26.
Alloui-Cros. “Mastering Both the Pen and the Sword?”
Marcus and Davis. “Cicero.”
Bae, Sebastian J. “Put Educational Wargaming in the Hands of the Warfighter.” War on the Rocks (July 13, 2023). URL: https://warontherocks.com/2023/07/put-educational-wargaming-in-the-hands-of-the-warfighter/.
Gweon, Hyowon, Fan, Judith, and Kim, Been. “Socially Intelligent Machines That Learn from Humans and Help Humans Learn.” Philosophical Transactions of the Royal Society A 381 (June 5, 2023). DOI: https://doi.org/10.1098/rsta.2022.0048.
Siddiqui, Faiz and Merrill, Jeremy B. “17 Fatalities, 736 Crashes.” The Washington Post (June 10, 2023). URL: https://www.washingtonpost.com/technology/2023/06/10/tesla-autopilot-crashes-elon-musk/.
Galitsky, Boris, Ilvovsky, Dmitry, and Goldberg, Saveli. “Shaped-Charge Learning Architecture for the Human-Machine Teams.” Entropy 25 (2023): pp. 22-23. DOI: https://doi.org/10.3390/e25060924.
Marcus and Davis. “Cicero.”
Garzez, Artur d’Avila and Lamb, Luís C. “Neurosymbolic AI: The 3rd Wave.” Artificial Intelligence Review (March 15, 2023). pp. 1-21. DOI: https://doi.org/10.1007/s10462-023-10448-w.
Sheth, Amit, Roy, Kaushik, and Gaur, Manas. “Neurosymbolic Artificial Intelligence (Why, What, and How).” IEEE Intelligent Systems 38 (May-June 2023): pp. 56-62. DOI: https://doi.org/10.1109/MIS.2023.3268724.
Scharre, Paul. Four Battlegrounds: Power in the Age of Artificial Intelligence. W.W. Norton & Company (2023): p. 266.
Wolfram, Stephen. “What Is ChatGPT Doing…and Why Does It Work?” Stephen Wolfram Writings (February 14, 2023). URL: https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/.